---
title: "La desigualdad en el mundo occidental"
description: |
Análisis de la desigualdad dentro de las regiones y los países occidentales
author:
- name: Jaume Garcia
affiliation: Universitat de València
affiliation-url: https://www.uv.es
date: 2026-01-03 #--
categories: [trabajo BigData, macroeconomía] #--
image: "./imagenes/global.jpg"
title-block-banner: "./imagenes/banner.jpg" #- {true, false, "green","#AA0000"}
title-block-banner-color: "orange" #-"#FFFFFF"
toc: true
toc-title: "Índice de contenidos"
toc-depth: 3
smooth-scroll: true
format:
html:
#backgroundcolor: "#F1F3F4"
#embed-resources: true
code-fold: true #-- Crea la pestaña "Ver código"
code-summary: "Mostrar código" #-- Texto que aparece en la pestaña
code-tools: true #-- Añade el botón global de herramientas de código
code-link: true #-- Hace que las funciones tengan links a la documentación
link-external-newwindow: true
#css: assets/my_css_file.css #- CUIDADO!!!!
#code-tools: true
#code-link: true
---
## Metodología
Para llevar a cabo este trabajo he utilizado datos de las fuentes que puedes encontrar al final en el apartado de Webgrafía. Los paquetes que he utilizado así como también el código de los distintos gráficos que he hecho a lo largo del trabajo los puedes ver pulsando las respectivas pestañas del código que aparecen a lo largo del documento. Obviamente, todo el código está hecho con el lenguaje de programación R.
He estructurado el trabajo de manera que podamos hacer un repaso de como ha evolucionado la desigualdad en los países occidentales para encontrar que factores podrían explicar la desigualdad. Cabe recalcar que el trabajo solo tiene en cuenta la región de Europa, Norteamérica y Oceanía. En principio el trabajo era para ambas regiones, pero a la vista de falta de datos, algunos gráficos contienen solo los países más importantes de dichas dos regiones.
## Introducción
Durante los últimos siglos el nivel de vida se ha incrementado exponencialmente en gran parte del mundo fruto de la revolución industrial y las subsiguientes globalizaciones, motor del desarrollo económico^[Para más información, véase: [“Is globalization an engine of economic development?”](https://ourworldindata.org/is-globalization-an-engine-of-economic-development)] (Ortiz-Ospina, 2017). Desde la primera revolución industrial que cita de finales del siglo 18 hasta los días que nos acontecen, la economía y la sociedad ha vivido un enorme progreso conducido por las disruptivas innovaciones que han ido surgiendo a raíz de grandes invenciones. Junto con las diferentes globalizaciones que se han producido a lo largo de la historia, gracias a estas podemos decir que gozamos de un mejor nivel de vida que nuestros antepasados (al menos los que vivimos en países industrializados).
En consecuencia, podemos consumir una gran variedad de bienes y servicios y a un bajo coste, diversificar nuestro riesgo. No obstante, no todo es color de rosas. La globalización conlleva sus riesgos, de antaño nos fuerza a depender en gran medida de otros, haciendonos más vulnerables . El mundo ha sufrido varias crisis, algunas de estas fruto de las dinámicas de la gobalización, además, de un creciente empeoramiento de las condiciones materiales a expendas de la mejoría de la parte más opulenta de la población.
La pobreza en términos absolutos ha ido desapareciendo en la esfera mundial, sin embargo, la desigualdad entre países y dentro de los países parece adentrarse en un terreno sin salida. Las grandes fortunas siguen acumulando riqueza sin parar, mientras gran parte de la población lucha por tener unos ingresos que le reporten un nivel de vida considerable. Esta desigualdad también puede verse como generacional, en los últimos años las personas en edad de jubilación han visto aumentar su riqueza y sus ingresos de manera considerable, en detrimento de los jóvenes que apenas han visto aumentar su capacidad económica. Así como también para los Estados Unidos, el país que más datos de carácter financiero ofrece, puede verse un aumento de la desigualdad tanto generacional como racional (entre distintas razas o región de procedencia)^[Para más información, véase: [“Distribution of Household Wealth in the U.S. since 1989”](https://www.federalreserve.gov/releases/z1/dataviz/dfa/distribute/chart/#range:1989.3,2025.2;quarter:143;series:Net%20worth;demographic:networth;population:all;units:levels)].
Con esto último, nos centraremos en la dinámica de la desigualdad a lo largo de las últimas décadas en los principales países occidentales (solo tendremos en cuenta para nuestro análisis a norte américa oceanía y europa, y en ocasiones, solamente los países más importantes de dichas regiones). Es decir, haremos un breve repaso de la evolución de la desigualdad, sus posibles desencadenantes y los ganadores y perdedores de esta.
Para alguno de los países occidentales, el aumento comercio como porcentaje del PIB es uno de los efectos de la globalización (libre movilidad de capitales, mercancías, personas, trabajo). Nos fijamos a partir del año 2000 su evolución.
```{r}
#PAQUETES USADOS:
library(tidyverse)
library(tidyr)
library(patchwork)
library(car)
library(WDI) #install.packages("WDI")
library(wbstats)
library(ggthemes)
library(scales)
library(OECD)
library(ggrepel)
library(gt)
library(stargazer)
#-------------------------------------
#EMPIEZA LO BUENO
df <- wb_data(indicator = "NE.EXP.GNFS.ZS",
start_date = 2000,
end_date = 2024)
df1 <- df %>%
select(country, date, NE.EXP.GNFS.ZS) %>%
rename(year = date, trade = NE.EXP.GNFS.ZS) %>%
mutate(year = as.numeric(year)) %>%
arrange(country, year) %>%
group_by(country) %>%
filter(any(year == 2000 & !is.na(trade))) %>%
mutate(base_trade = trade[year == 2000],
index_nums = trade / base_trade * 100) %>%
filter(!is.na(index_nums)) %>%
ungroup()
paises_destacados <- c("Spain", "United States", "Germany", "Poland", "France", "Italy", "Ireland", "Australia", "Canada", "Portugal")
df_fondo <- df1 %>% filter(!country %in% paises_destacados)
df_foco <- df1 %>% filter(country %in% paises_destacados)
plot_comercio <- ggplot() +
geom_line(data = df_fondo, aes(x = year, y = index_nums, group = country),
color = "grey", size = 0.4, alpha = 0.8) +
geom_line(data = df_foco, aes(x = year, y = index_nums, color = country),
size = 1.2) +
geom_text_repel(data = df_foco %>% filter(year == max(year)),
aes(x = year, y = index_nums, label = country, color = country),
hjust = 0, nudge_x = 0.5, direction = "y", fontface = "bold", size = 4) +
scale_color_brewer(palette = "Dark2") +
scale_x_continuous(breaks = seq(2000, 2024, by = 4), expand = expansion(mult = c(0, 0.15))) +
labs(title = "Evolución del comercio como % del PIB",
subtitle = "Perspectiva del mundo occidental (Índice 2000 = 100)",
caption = "Fuente: elaboración propia a partir del Banco Mundial",
x = "",
y = "") +
theme_minimal(base_family = "Times New Roman") +
theme(
legend.position = "none",
plot.title = element_text(size = 18, face = "bold", color = "#2c3e50"),
plot.subtitle = element_text(size = 12, color = "grey40", margin = margin(b = 20)),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
axis.text = element_text(size = 10, color = "grey30"))
plot_comercio
plot_comercio_2 <- ggplot() +
geom_line(data = df_fondo, aes(x = year, y = index_nums, group = country),
color = "grey", size = 0.4, alpha = 0.8) +
geom_line(data = df_foco, aes(x = year, y = index_nums, color = country),
size = 1.2) +
geom_text_repel(data = df_foco %>% filter(year == max(year)),
aes(x = year, y = index_nums, label = country, color = country),
hjust = 0, nudge_x = 0.5, direction = "y", fontface = "bold", size = 4) +
scale_color_brewer(palette = "Dark2") +
scale_x_continuous(breaks = seq(2000, 2024, by = 4), expand = expansion(mult = c(0, 0.15))) +
coord_cartesian(ylim = c(20, 240)) +
labs(title = "Evolución del comercio como % del PIB",
subtitle = "Perspectiva del mundo occidental (Índice 2000 = 100)",
caption = "Fuente: elaboración propia a partir del Banco Mundial",
x = "",
y = "") +
theme_minimal(base_family = "Times New Roman") +
theme(
legend.position = "none",
plot.title = element_text(size = 18, face = "bold", color = "#2c3e50"),
plot.subtitle = element_text(size = 12, color = "grey40", margin = margin(b = 20)),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
axis.text = element_text(size = 10, color = "grey30"))
plot_comercio_2
```
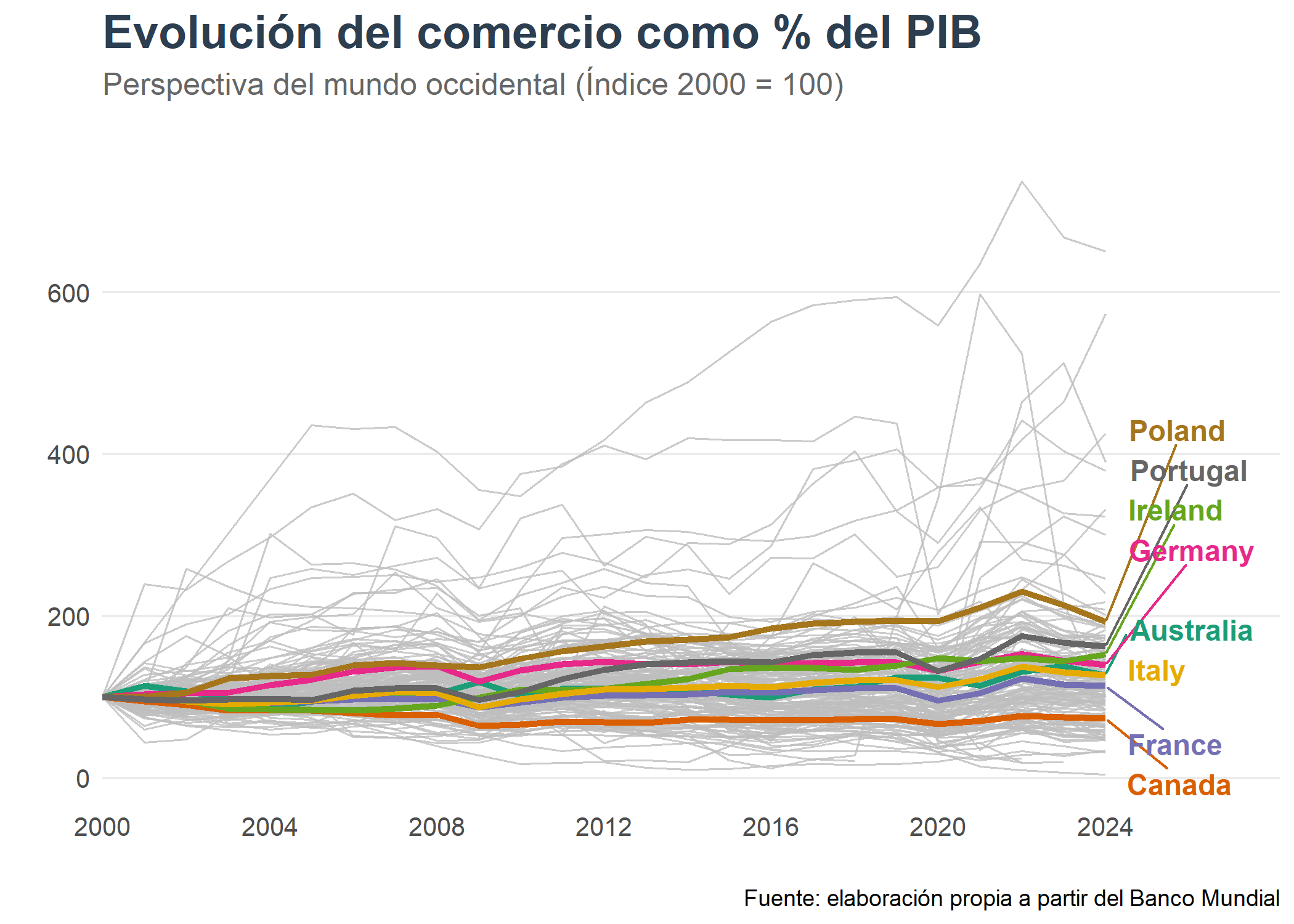
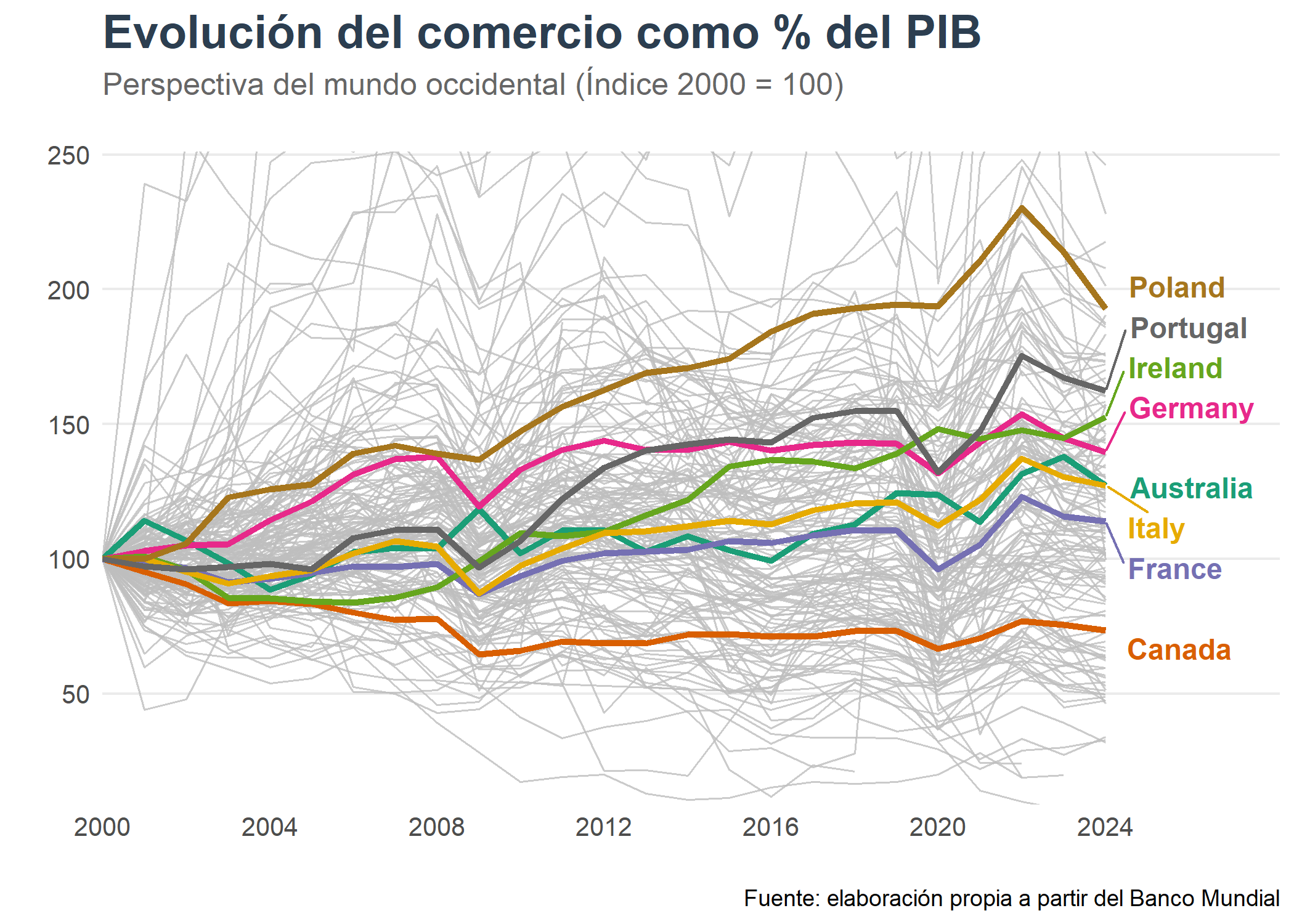
El comercio como el porcentaje del PIB desde el año 2000 ha aumentado en gran parte de los países analizados, siendo el que más Polonia, Portugal e Irlanda. Estos últimos, considerados desde no hace mucho tiempo países pobres europeos, han encabezado el aumento del comercio como porcentaje del PIB. Por otra parte, Canada es el único país que no ha visto incrementar su comercio con respecto el PIB desde el año 2000, posiblemente debido a que su boom expansionista comercial fue en la última década del siglo pasado tras el acuerdo comercial NAFTA^[Para más información, véase: [“Tratado de Libre Comercio de América del Norte”](https://es.wikipedia.org/wiki/Tratado_de_Libre_Comercio_de_Am%C3%A9rica_del_Norte)].
---
## ¿Qué parte del ingreso y riqueza nacional acapara el 1% más rico?
La desigualdad entre agentes económicos dentro de una región o país no ha parado de crecer. Cada vez más, una pequeña parte de la población, que es la más adinerada, acumula una mayor parte de los ingresos y la riqueza nacional. Desde mitad del siglo XIX, la distribución de la renta y la riqueza se ha vuelto mermada hacia la desigualdad. Algunos autores argumentan que las políticas neoliberales llevadas a cabo en los años 80 han auspiciado esta desigualdad, mientras que otros argumentan las rigideces que siguen vigentes en la economía.
```{r}
ruta <- "./links/WID_Data_23112025-000046.csv"
df_wdi <- rio::import(ruta)
as.data.frame(df_wdi)
df_wdi_1 <- df_wdi %>%
rename(region = c(1), year = c(4), values = c(5)) %>%
pivot_wider(names_from = V2, values_from = values) %>%
rename(eur_national_income_10 = c(4), eur_national_income_01 = c(5), eur_national_wealth_10 = c(6), eur_national_wealth_01 = c(7), nor_oce_national_income_10 = c(8), nor_oce_national_income_01 = c(9), nor_oce_national_wealth_10 = c(10), nor_oce_national_wealth_01 = c(11))
str(df_wdi_1)
df_long <- df_wdi_1 %>%
select(year,
Europe_Income = eur_national_income_01,
Europe_Wealth = eur_national_wealth_01,
NorthAm_Income = nor_oce_national_income_01,
NorthAm_Wealth = nor_oce_national_wealth_01) %>%
pivot_longer(
cols = -year,
names_to = "category",
values_to = "percentage"
) %>%
separate(category, into = c("Region", "Metric"), sep = "_") %>%
filter(!is.na(percentage))
head(df_long)
plot_final <- ggplot(df_long, aes(x = year, y = percentage, color = Region)) +
geom_line(size = 1.2) +
facet_wrap(~Metric,
scales = "free_y",
labeller = as_labeller(c(
"Income" = "Participación en el INGRESO (Top 1%)",
"Wealth" = "Participación en la RIQUEZA (Top 1%)"
))) +
scale_color_manual(
values = c("Europe" = "#2C3E50", "NorthAm" = "#E74C3C"),
labels = c("Europe" = "Europa", "NorthAm" = "Norteamérica")
) +
scale_y_continuous(
expand = expansion(mult = c(0.05, 0.2)) ) +
scale_x_continuous(breaks = seq(1980, 2024, by = 10)) +
labs(
title = "La brecha transatlántica de desigualdad",
subtitle = "Porcentaje del total nacional capturado por el 1% más rico para las distintas regiones",
caption = "Fuente: Elaboración propia a partir del World Inequality Database (WID)",
x = "",
y = "% del Total Nacional",
color = "") +
theme_minimal(base_family = "sans") +
theme(
legend.position = "top",
legend.justification = "left",
plot.title = element_text(face = "bold", size = 16),
strip.text = element_text(face = "bold", size = 11),
strip.background = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.minor = element_blank(),
axis.line.x = element_line(color = "black"))
plot_final
#------------------
ruta_ <- "./links/WID_Metadata_29112025-213308.csv"
df_gdp <- rio::import(ruta_)
as.data.frame(df_gdp)
str(df_gdp)
df_gdp <- df_gdp %>% rename(region = c(1), variable = c(2), year = c(4), gdp_per_capita = c(5)) %>%
select(-c(3))
df_plot <- df_gdp %>%
arrange(region, year) %>%
group_by(region) %>%
mutate(index_value = gdp_per_capita / first(gdp_per_capita) * 100) %>%
ungroup() %>%
filter(region %in% c("Europe (MER)", "North America & Oceania (MER)"))
colors_eco <- c("Europe (MER)" = "#004862",
"North America & Oceania (MER)" = "#961c20")
df_plot_gdp <- df_gdp %>%
arrange(region, year) %>%
group_by(region) %>%
mutate(index_value = gdp_per_capita / first(gdp_per_capita) * 100) %>%
ungroup() %>%
filter(region %in% c("Europe (MER)", "North America & Oceania (MER)"))
colors_modern <- c("Europe (MER)" = "#2C3E50",
"North America & Oceania (MER)" = "#E74C3C")
ggplot(df_plot_gdp, aes(x = year, y = index_value, color = region)) +
geom_line(size = 1.3) +
geom_point(data = df_plot_gdp %>% group_by(region) %>% filter(year == max(year)),
size = 3) +
scale_color_manual(
values = colors_modern,
labels = c("Europa (MER)", "Norteamérica y Oceanía (MER)")
) +
scale_y_continuous(
limits = c(90, NA),
expand = expansion(mult = c(0, 0.1))
) +
scale_x_continuous(breaks = seq(1960, 2030, by = 10)) +
labs(
title = "La Divergencia del Crecimiento Económico",
subtitle = "Evolución del PIB per cápita real (Índice Base 1960 = 100)",
caption = "Fuente: Elaboración propia a partir del World Inequality Database (WID)",
x = "",
y = "",
color = ""
) +
theme_minimal(base_family = "sans") +
theme(
legend.position = "top",
legend.justification = "left",
legend.direction = "horizontal",
legend.text = element_text(size = 11, face = "bold", color = "#444444"),
legend.margin = margin(l = -10, b = 10),
plot.title = element_text(face = "bold", size = 18, color = "#222222"),
plot.subtitle = element_text(size = 12, color = "#555555", margin = margin(b = 20)),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_line(color = "grey90", linetype = "dashed"),
axis.text = element_text(size = 10, color = "#666666"),
axis.line.x = element_line(color = "black", size = 0.5)
)
df_plot_real <- df_gdp %>%
filter(region %in% c("Europe (MER)", "North America & Oceania (MER)"))
colors_modern <- c("Europe (MER)" = "#2C3E50",
"North America & Oceania (MER)" = "#E74C3C")
ggplot(df_plot_real, aes(x = year, y = gdp_per_capita, color = region)) +
geom_line(size = 1.3) +
geom_point(data = df_plot_real %>% group_by(region) %>% filter(year == max(year)),
size = 3) +
scale_color_manual(
values = colors_modern,
labels = c("Europe (MER)" = "Europa", "North America & Oceania (MER)" = "Norteamérica y Oceanía")
) +
scale_y_continuous(
labels = scales::number_format(big.mark = ".", decimal.mark = ","),
limits = c(0, NA),
expand = expansion(mult = c(0, 0.1))
) +
scale_x_continuous(breaks = seq(1960, 2034, by = 10)) +
labs(
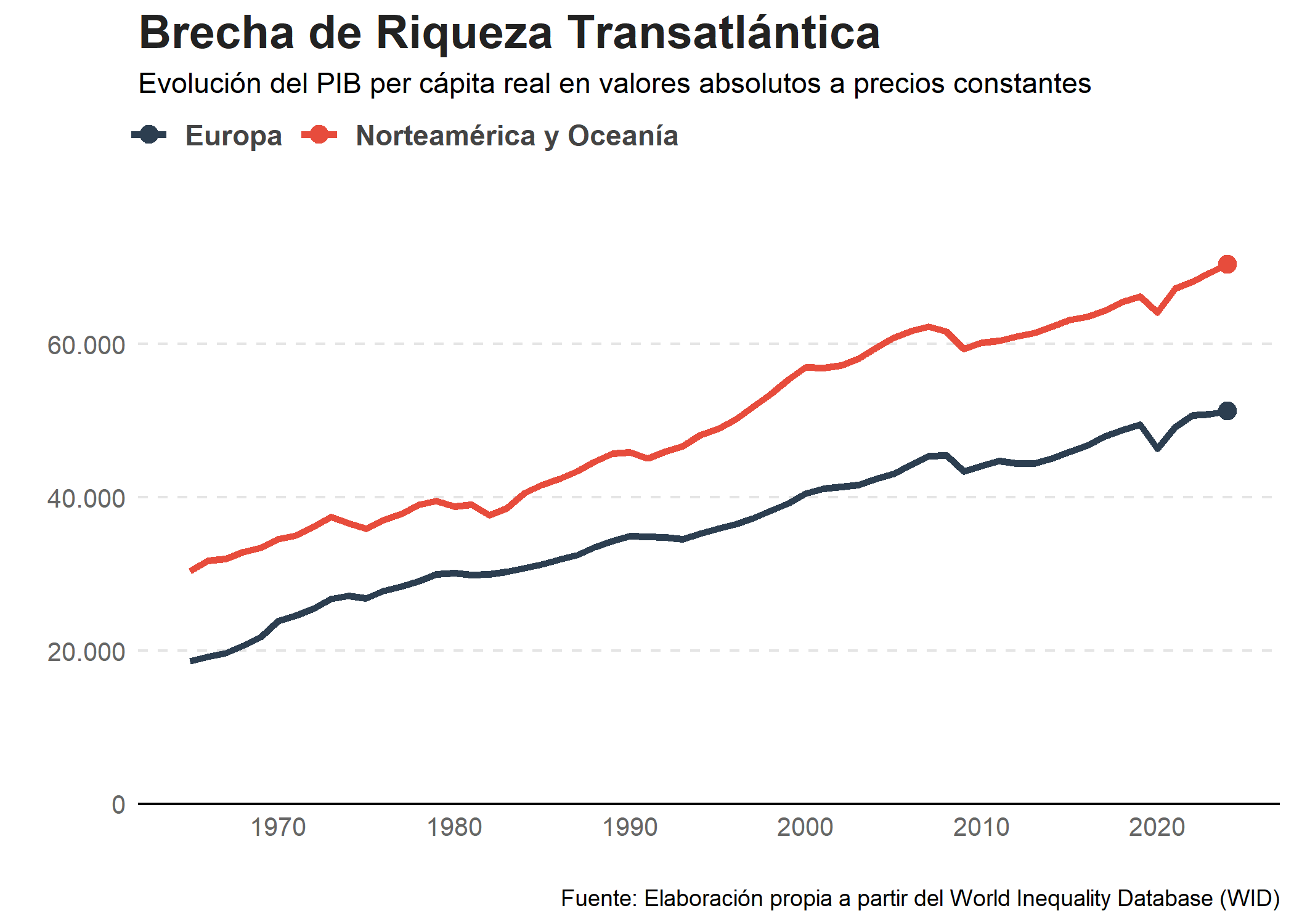
title = "Brecha de Riqueza Transatlántica",
subtitle = "Evolución del PIB per cápita real en valores absolutos a precios constantes",
caption = "Fuente: Elaboración propia a partir del World Inequality Database (WID)",
x = "",
y = "",
color = ""
) +
theme_minimal(base_family = "sans") +
theme(
legend.position = "top",
legend.justification = "left",
legend.direction = "horizontal",
legend.text = element_text(size = 11, face = "bold", color = "#444444"),
legend.margin = margin(l = -10, b = 10),
plot.title = element_text(face = "bold", size = 18, color = "#222222"),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(), # Solo líneas horizontales
panel.grid.major.y = element_line(color = "grey90", linetype = "dashed"),
axis.text = element_text(size = 10, color = "#666666"),
axis.line.x = element_line(color = "black", size = 0.5)
)
```
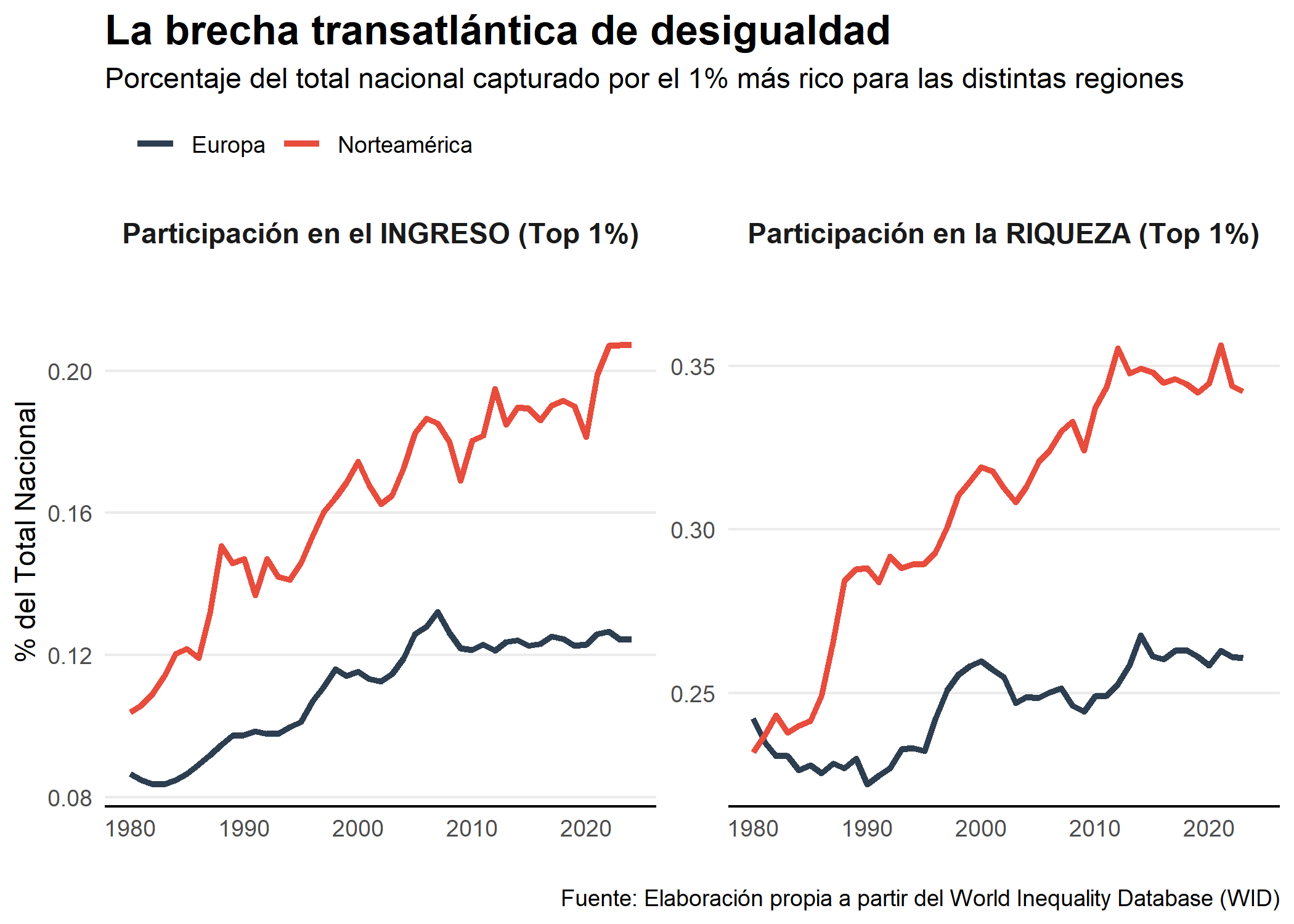
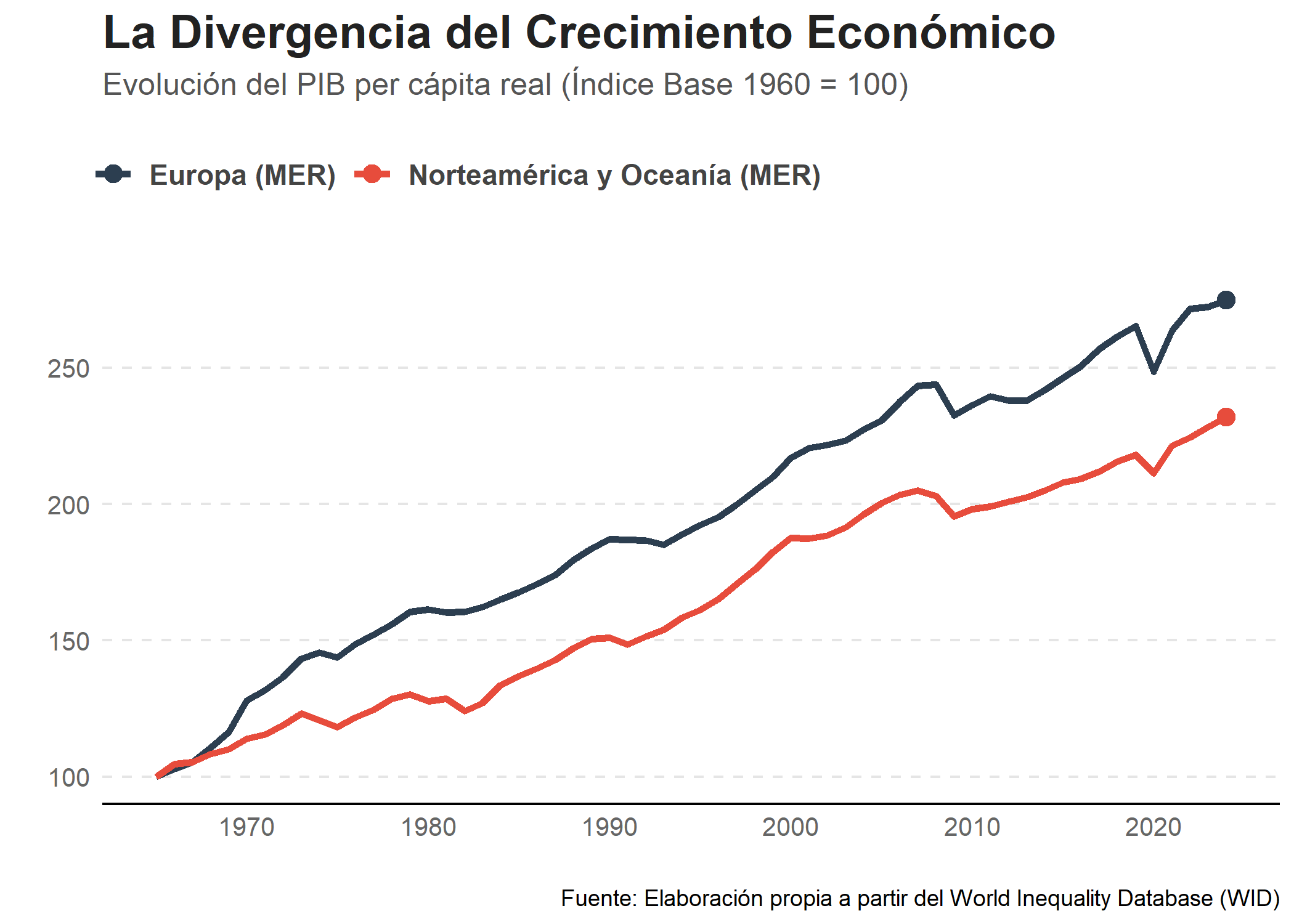
En América del norte y Oceanía, la desigualdad se ha incrementado en mayor proporción en comparación a Europa. A simple vista podría hacernos creer que las políticas desreguladoras aplicadas en la región anglosajona han mermado la igualdad económica de su población. No obstante, en Europa donde algunos países gozan de la etiqueta de socialistas, la desigualdad no se ha visto reducida.
## El capital y el trabajo
El capital y el trabajo son factores productivos necesarios para la producción. Estos han sido complementarios y las dinámicas de su uso han ido cambiando durante las distintas innovaciones que se han producido a lo largo de la historia. Muchos autores culpan al capital de ser el causante de la desigualdad aludiendo a su expansión acaparadora sobre la renta nacional en detrimento del factor trabajo.
```{r}
ruta_ <- "./links/L_K_Share.csv"
df_LK <- rio::import(ruta_)
as.data.frame(df_LK)
str(df_LK)
data_LK <- df_LK %>% rename(year = c(2), labor_share_NA = c(3), labor_share_EU = c(4), capital_share_NA = c(5), capital_share_EU = c(6))
data_LK <- data_LK %>% select(-c(1))
data_long <- data_LK %>%
pivot_longer(
cols = -year,
names_to = "variable",
values_to = "porcentaje") %>%
mutate(region = case_when(
str_detect(variable, "NA") ~ "Norteamérica",
str_detect(variable, "EU") ~ "Europa"),
factor = case_when(
str_detect(variable, "labor") ~ "Trabajo",
str_detect(variable, "capital") ~ "Capital")) %>%
group_by(region, year) %>%
mutate(porcentaje = porcentaje / sum(porcentaje, na.rm = TRUE) *100) %>%
ungroup()
plot_LK_area <- data_long %>%
mutate(factor = factor(factor, levels = c("Capital", "Trabajo"))) %>%
ggplot(aes(x = year, y = porcentaje, fill = factor)) +
geom_area(alpha = 0.9, color = "white", linewidth = 0.1) +
facet_wrap(~region) +
scale_fill_manual(values = c("Trabajo" = "#E69F00", "Capital" = "#0072B2")) +
scale_x_continuous(limits = c(1960, 2023), breaks = seq(1960, 2020, by = 15)) +
scale_y_continuous(labels = scales::percent_format(scale = 1), expand = c(0,0)) +
theme_minimal(base_size = 13) +
theme(plot.title = element_text(size = 18, face = "bold", color = "#2c3e50"),
plot.subtitle = element_text(color = "#7f8c8d", margin = margin(b = 15)),
legend.position = "top",
legend.title = element_blank(),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
strip.text = element_text(size = 14, face = "bold", color = "#2c3e50"),
strip.background = element_rect(fill = "#ecf0f1", color = NA),
plot.background = element_rect(fill = "white", color = NA),
panel.spacing = unit(2, "lines")) +
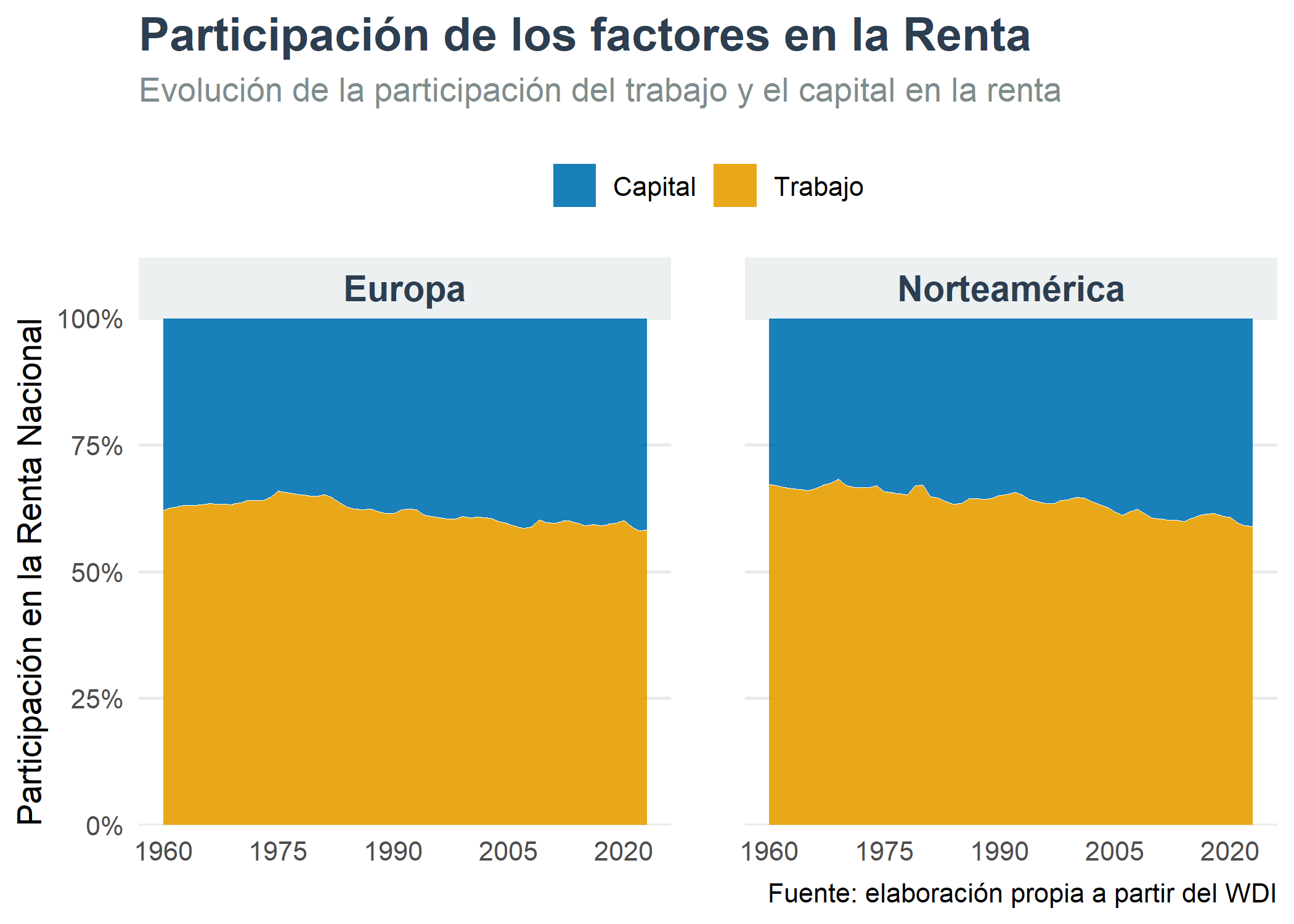
labs(title = "Participación de los factores en la Renta",
subtitle = "Evolución de la participación del trabajo y el capital en la renta",
caption = "Fuente: elaboración propia a partir del WDI",
x = NULL,
y = "Participación en la Renta Nacional")
plot_LK_area
```
En Norte América el capital ha ido ganando terreno sobre el trabajo en su participación en la renta nacional. En europa, el efecto es el mismo pero en menor proporción.
## Productividad
Todos estamos de acuerdo en que la productividad laboral se ha incrementado debido a las innovaciones tecnológicas sobretodo en el último cuarto del siglo anterior donde la revolución de las TIC han entrado con fuerza y han revolucionado la economía digital tal y como la conocemos a día de hoy. Distintos artículos evidencian un pay gap^[Para más información, véase: [“The Productivity–Pay Gap”](https://es.wikipedia.org/wiki/Tratado_de_Libre_Comercio_de_Am%C3%A9rica_del_Norte)] donde los salarios no se han visto compensados a la par con la productividad, la cual cosa a simple vista indicaría que los empresarios estarían abusando de su poder sobre los trabajadores.
```{r}
ruta_ <- "./links/productividad.csv"
df_productividad <- rio::import(ruta_)
as.data.frame(df_productividad)
df_productividad <- df_productividad %>% select(c(2), year = c(3), value = c(4))
df_prod_plot <- df_productividad %>%
rename(country = Code) %>%
arrange(country, year) %>%
group_by(country) %>%
mutate(index = value / first(value) * 100) %>%
ungroup() %>%
filter(country != "NZL")
ggplot(df_prod_plot, aes(x = year, y = index, color = country)) +
geom_line(size = 1.2, alpha = 0.9) +
geom_point(data = df_prod_plot %>% group_by(country) %>% filter(year == max(year)),
size = 2.5) +
geom_text_repel(
data = df_prod_plot %>% group_by(country) %>% filter(year == max(year)),
aes(label = country),
size = 4,
fontface = "bold",
direction = "y",
nudge_x = 2,
hjust = 0,
segment.color = "grey50",
segment.size = 0.5
) +
scale_color_brewer(palette = "Dark2") +
scale_x_continuous(
limits = c(min(df_prod_plot$year), max(df_prod_plot$year) + 10),
breaks = seq(1960, 2030, by = 10)
) +
scale_y_continuous(
breaks = seq(0, 1000, by = 50),
expand = expansion(mult = c(0.05, 0.05))
) +
labs(
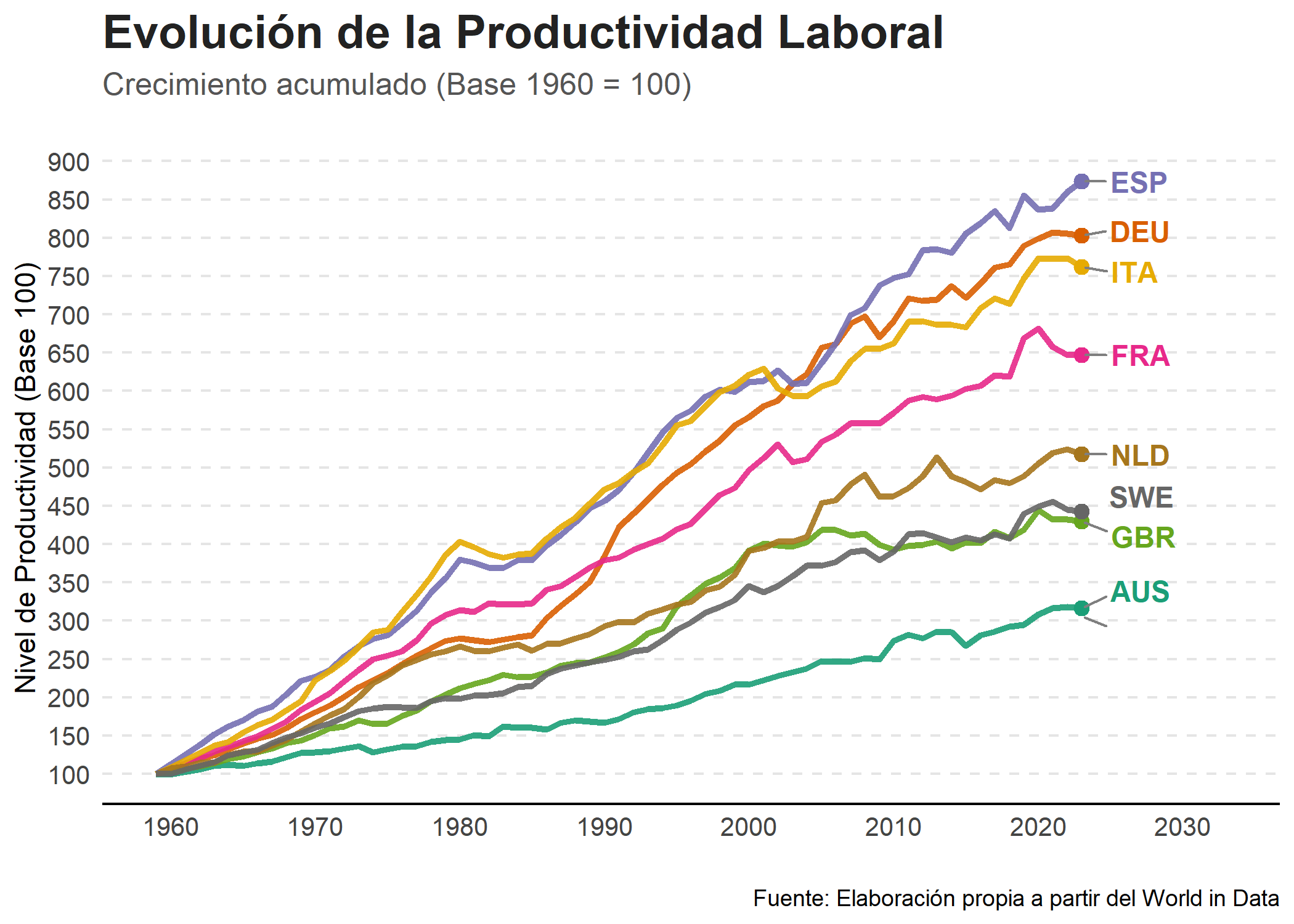
title = "Evolución de la Productividad Laboral",
subtitle = "Crecimiento acumulado (Base 1960 = 100)",
caption = "Fuente: Elaboración propia a partir del World in Data",
x = "",
y = "Nivel de Productividad (Base 100)"
) +
theme_minimal(base_family = "sans") +
theme(
legend.position = "none",
plot.title = element_text(face = "bold", size = 18, color = "#222222"),
plot.subtitle = element_text(size = 12, color = "#555555", margin = margin(b = 20)),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_line(color = "grey90", linetype = "dashed"),
axis.text = element_text(size = 10, color = "#444444"),
axis.line.x = element_line(color = "black", size = 0.5)
)
```
Gráficamente podemos observar como la productividad laboral ha crecido a muy buen ritmo desde el año 1960. Desde luego, en dichos países no se han visto subidas salariales a tales tasas de crecimiento.
## Hipótesis de Piketty
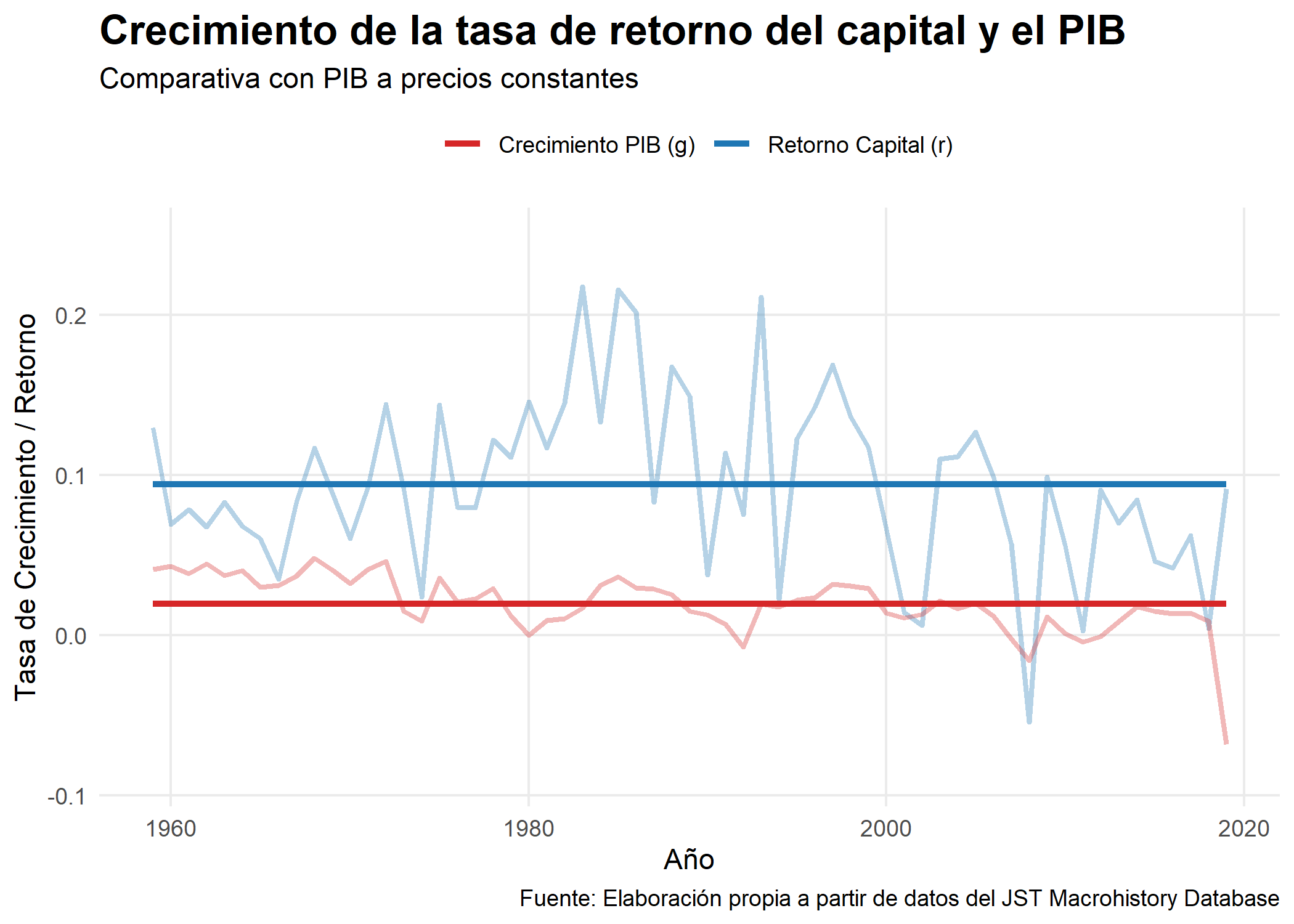
El famoso libro de Thomas Piketty (El capital en el siglo XXI) nos dice que la desigualdad ha crecido por el mayor aumento de la tasa de retorno del capital frente al crecimiento del PIB, el famoso r > g. Mientras que el análisis de Thomas Piketty es de los últimos siglos, nosotros hacemos un análisis para las últimas décadas, mientras que el análisis de Thomas Piketty es de los últimos siglos. No obstante, otros autores como Juan Ramón Rallo han criticado su obra argumentando que que la inversión pasada del ahorro no garantiza rentabilidades futuras y que el valor del capital sólo puede sostenerse en el tiempo en tanto en cuanto sea capaz de seguir generando rentas futuras^[Para más información, véase: [“LEYENDO A PIKETTY: R>G”](https://juanramonrallo.com/leyendo-a-piketty-rg/)].
```{r}
ruta_ <- "./links/JSTdatasetr6.xlsx"
df_ret <- rio::import(ruta_)
as.data.frame(df_productividad)
options(scipen = 999)
df_ret <- df_ret %>% select(c(1,2,8,41,42,43,44))
df_ret <- df_ret %>% filter(!country %in% c("Japan", "Canada", "Ireland")) %>%
filter(year %in% c(1959:2020)) %>%
rename(gdp = c(3))
df_ret_1 <- df_ret %>% group_by(country) %>%
mutate(r = (eq_tr + housing_tr + bond_tr + bill_rate) / 4) %>%
mutate(g = (lead(gdp) / gdp) - 1) %>%
mutate(d = r - g) %>%
ungroup()
df_ret_1 <- df_ret %>%
group_by(country) %>%
mutate(
r = (eq_tr + housing_tr + bond_tr + bill_rate) / 4,
g = (dplyr::lead(gdp) / gdp) - 1,
d = r - g
) %>%
ungroup()
df_ret_1 <- df_ret_1 %>% group_by(year) %>%
mutate(r_all = mean(r, na.rm = TRUE)) %>%
mutate(g_all = mean(g, na.rm = TRUE)) %>%
mutate(d_all = mean(d, na.rm = TRUE)) %>%
ungroup() %>%
summarise(year, r_all, g_all, d_all) %>%
distinct() %>%
slice(-c(62)) %>%
mutate(m_r = mean(r_all),
m_g = mean(g_all))
plot_ret <- df_ret_1 %>% ggplot(aes(x = year, y = r_all)) +
geom_line(color = "#1f77b4", size = 0.9, alpha = 0.33, font = "bold") +
geom_line(aes(y = g_all), color = "#d62728", alpha = 0.33, size = 0.9, font = "bold") +
geom_line(aes(y = m_r, color = "Retorno Capital (r)"), size = 1.2) +
geom_line(aes(y = m_g, color = "Crecimiento PIB (g)"), size = 1.2) +
scale_color_manual(name = "",
values = c("Retorno Capital (r)" = "#1f77b4",
"Crecimiento PIB (g)" = "#d62728")) +
scale_y_continuous(limits = c(-0.09, 0.25)) +
labs(title = "Crecimiento de la tasa de retorno del capital y el PIB",
subtitle = "Comparativa con PIB a precios constantes",
y = "Tasa de Crecimiento / Retorno",
x = "Año",
caption = "Fuente: Elaboración propia a partir de datos del JST Macrohistory Database") +
theme_minimal() +
theme(
plot.title = element_text(face = "bold", size = 16),
legend.position = "top",
panel.grid.minor = element_blank()) +
NULL
plot_ret
```
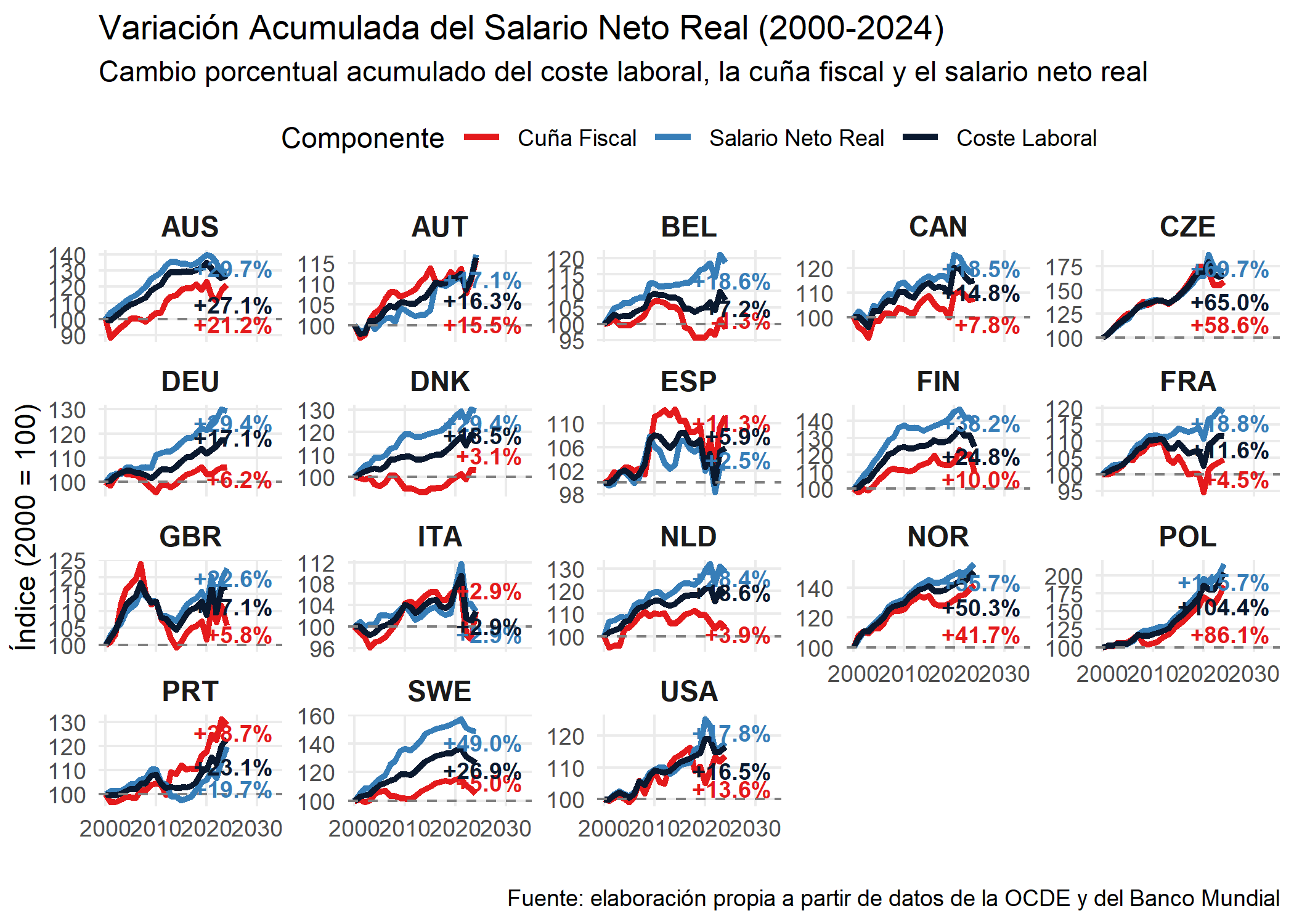
## ¿Infierno fiscal para el trabajo?
En consonancia con el análisis de la evolución del salario real del ingeniero Jon González para España en los últimos años^[Para más información, véase:[https://x.com/Jongonzlz/status/2005663335073640718](https://x.com/Jongonzlz/status/2005663335073640718)], este apartado analizará si ocurre lo mismo en los distintos países. Es decir, si con el aumento de la carga fiscal a los trabajadores se produce una reducción del salario neto real a pesar del aumento de la productividad y del salario bruto. Viendo el análisis de Jon González, en España apenas ha aumentado el salario neto real a pesar del aumento del salario bruto real. Con el aumento de la carga tributaria del Estado, nos lleva a concluir que el Estado con instrumentos fiscales (cotizaciones e impuestos) le ha quitado una buena parte de la remuneración salarial al trabajo. ¿Ocurrirá lo mismo para los distintos países europeos?
Cabe recalcar que la imposición fiscal sobre el trabajo y el capital dista bastante de ser equitativo. La imposición sobre el capital se beneficia de menores tasas y de mayores deducciones en comparación con el factor trabajo. (Hourani et al., 2023) analizan la imposición sobre ambos factores con la conclusión general de una menor imposición sobre los ingresos de dividendos y ganancias sobre el capital en comparación a los impuestos sobre el trabajo^[Para más información, véase: ["The taxation of labour vs capital income: A focus on high earners"](https://www.oecd.org/content/dam/oecd/en/publications/reports/2023/08/the-taxation-of-labour-vs-capital-income_0d35e3e3/04f8d936-en.pdf)].
```{r}
df_wdi <- WDI(country = c("AU", "AT", "BE", "CA", "CZ", "DK",
"FI", "FR", "DE", "IT", "NL", "NO",
"PL", "PT", "ES", "SE", "GB", "US"),
indicator = c("ppp_factor" = "PA.NUS.PPP",
"gdp_deflator" = "NY.GDP.DEFL.ZS"),
start = 2000, end = 2024) %>%
as_tibble() %>%
rename(pais_iso2 = iso2c) %>%
mutate(pais = case_when(
pais_iso2 == "AU" ~ "AUS", pais_iso2 == "AT" ~ "AUT", pais_iso2 == "BE" ~ "BEL",
pais_iso2 == "CA" ~ "CAN", pais_iso2 == "CZ" ~ "CZE", pais_iso2 == "DK" ~ "DNK",
pais_iso2 == "FI" ~ "FIN", pais_iso2 == "FR" ~ "FRA", pais_iso2 == "DE" ~ "DEU",
pais_iso2 == "IT" ~ "ITA", pais_iso2 == "NL" ~ "NLD", pais_iso2 == "NO" ~ "NOR",
pais_iso2 == "PL" ~ "POL", pais_iso2 == "PT" ~ "PRT", pais_iso2 == "ES" ~ "ESP",
pais_iso2 == "SE" ~ "SWE", pais_iso2 == "GB" ~ "GBR", pais_iso2 == "US" ~ "USA"
)) %>%
select(pais, year, ppp_factor, gdp_deflator)
ruta_ <- "./links/odce_clu_tax.csv"
df_clu_tax <- rio::import(ruta_)
df_base <- df_clu_tax %>%
filter(
UNIT_MEASURE == "USD_PPP",
MEASURE %in% c("GEBT", "NIAT", "GLCBT"),
HOUSEHOLD_TYPE == "S_C0",
INCOME_PRINCIPAL == "AW100",
REF_AREA %in% c("AUS", "AUT", "BEL", "CAN", "CZE", "DNK",
"FIN","FRA", "DEU", "ITA", "NLD","NOR",
"POL", "PRT","ESP", "SWE", "GBR","USA")
) %>%
select(pais = REF_AREA, variables = MEASURE, year = TIME_PERIOD, value_ppp = OBS_VALUE)
df_wdi <- WDI(country = c("AU", "AT", "BE", "CA", "CZ", "DK",
"FI", "FR", "DE", "IT", "NL", "NO",
"PL", "PT", "ES", "SE", "GB", "US"),
indicator = c("ppp_factor" = "PA.NUS.PPP",
"CPI" = "FP.CPI.TOTL"),
start = 2000, end = 2024) %>%
as_tibble() %>%
rename(pais_iso2 = iso2c) %>%
mutate(pais = case_when(
pais_iso2 == "AU" ~ "AUS", pais_iso2 == "AT" ~ "AUT", pais_iso2 == "BE" ~ "BEL",
pais_iso2 == "CA" ~ "CAN", pais_iso2 == "CZ" ~ "CZE", pais_iso2 == "DK" ~ "DNK",
pais_iso2 == "FI" ~ "FIN", pais_iso2 == "FR" ~ "FRA", pais_iso2 == "DE" ~ "DEU",
pais_iso2 == "IT" ~ "ITA", pais_iso2 == "NL" ~ "NLD", pais_iso2 == "NO" ~ "NOR",
pais_iso2 == "PL" ~ "POL", pais_iso2 == "PT" ~ "PRT", pais_iso2 == "ES" ~ "ESP",
pais_iso2 == "SE" ~ "SWE", pais_iso2 == "GB" ~ "GBR", pais_iso2 == "US" ~ "USA"
)) %>%
select(pais, year, ppp_factor, CPI)
df_final <- left_join(df_base, df_wdi, by = c("pais", "year")) %>%
drop_na()
df_calc <- df_final %>%
mutate(value_nc = value_ppp * ppp_factor) %>%
select(pais, year, variables, value_nc, CPI) %>%
pivot_wider(names_from = variables, values_from = value_nc) %>%
group_by(pais) %>%
mutate(
pp_glcbt = GLCBT / (CPI/100),
pp_niat = NIAT / (CPI/100),
pp_wedge = pp_glcbt - pp_niat,
index_pp_glcbt = pp_glcbt / first(pp_glcbt) * 100,
index_pp_niat = pp_niat / first(pp_niat) * 100,
index_pp_wedge = pp_wedge / first(pp_wedge) * 100) %>%
ungroup()
df_plot <- df_calc %>%
select(pais, year, index_pp_niat, index_pp_wedge, index_pp_glcbt) %>%
pivot_longer(cols = starts_with("index"),
names_to = "Componente",
values_to = "Index") %>%
mutate(Componente = factor(Componente, levels = c("index_pp_wedge", "index_pp_niat", "index_pp_glcbt")))
etiqueta <- df_plot %>%
group_by(pais, Componente) %>%
filter(year == max(year)) %>%
ungroup() %>%
mutate(
diff = Index - 100,
label_text = sprintf("%+.1f%%", diff))
plot_tax_final <- ggplot(df_plot, aes(x = year, y = Index, color = Componente, group = Componente)) +
geom_line(linewidth = 1.2) +
facet_wrap(~pais, scales = "free_y") +
geom_hline(yintercept = 100, linetype = "dashed", color = "gray50", linewidth = 0.5) +
geom_text_repel(
data = etiqueta,
aes(label = label_text),
direction = "y",
nudge_x = 2,
hjust = 0,
size = 3.2,
fontface = "bold",
segment.color = NA,
show.legend = FALSE) +
scale_x_continuous(expand = expansion(mult = c(0.05, 0.35))) +
scale_color_manual(
values = c("index_pp_wedge" = "#E41A1C",
"index_pp_niat" = "#377EB8",
"index_pp_glcbt" = "#0A192F"),
labels = c("Cuña Fiscal", "Salario Neto Real", "Coste Laboral")) +
labs(
title = "Variación Acumulada del Salario Neto Real (2000-2024)",
subtitle = "Cambio porcentual acumulado del coste laboral, la cuña fiscal y el salario neto real",
y = "Índice (2000 = 100)",
x = "",
caption = "Fuente: elaboración propia a partir de datos de la OCDE y del Banco Mundial") +
theme_minimal() +
theme(
legend.position = "top",
strip.text = element_text(size = 11, face = "bold"),
panel.grid.minor = element_blank())
plot_tax_final
```
Como podemos observar, a excepción de España y Portugal, los salarios reales netos han aumentado por encima de la carga tributaria, lo que automáticamente nos lleva a decir que el Estado en estos países no ha propiciado a la baja el aumento del salario neto real para sus trabajadores. Por lo tanto, dejando de lado la diferencia impositiva entre el factor capital y el factor trabajo, el Estado no ha contribucido de manera significativa a reducir el salario neto. Cabe recalcar que esto no significa que la desigualdad disminuya.
## Determinante de la desigualdad
Para finalizar el trabajo, hacemos un análisis econométrico sencillo mediante mínimos cuadráticos ordinarios. Con esto, veremos que variables afectan más al coeficiente de Gini, es decir, veremos si alguna variable afecta significativamente a la otra para ver si podemos sacar alguna conclusión con este análisis. Añadiremos, además de la cuña fiscal que afecta a los trabajadores y la productividad y la inflación, la capitalización de mercado de las empresas como porcentaje del PIB y el precio de la vivienda.
$$
\begin{aligned}
\text{Gini}_i = \beta_0 & + \beta_1 \ln(\text{Tax Wedge}) + \beta_2 \ln(\text{Housing}) + \beta_3 \ln(\text{Productividad}) + \beta_4 \text{Market Cap} \ + \\
& \beta_5 \text{Inflacion} + \epsilon_i
\end{aligned}
$$
```{r}
ruta_ <- "./links/POP.csv"
df_GDP <- rio::import(ruta_)
as.data.frame(df_GDP)
#PRIMERO EL GDP TOTAL
df_GDP <- df_GDP %>% select(year = c(2), pop_eur = c(3), pop_nor = c(4), gdp_eur = c(5), gdp_nor = c(6))
df_GDP_ <- df_GDP %>% mutate(gdp_eur = pop_eur * gdp_eur,
gdp_nor = pop_nor * gdp_nor) %>%
select(c(1,4,5)) %>%
mutate(gdp_aggre = gdp_eur + gdp_nor,
gdp_aggre = gdp_aggre / 2) %>%
select(1,4)
#HAUS
ruta_ <- "./links/haus.csv"
df_haus <- rio::import(ruta_)
as.data.frame(df_haus)
df_haus <- df_haus %>% filter(Year %in% c(1980:2023)) %>%
select(year = c(2), haus_eur = c(3), haus_nor = c(4))
#LISTED COMPANIES
ruta_ <- "./links/market_cap.csv"
df_market <- rio::import(ruta_)
as.data.frame(df_market)
df_market <- df_market %>% select(pais = c(1), year = c(3), market_cap = c(4))
#GiNi iNDeX
ruta_ <- "./links/GiNi.csv"
df_Gini <- rio::import(ruta_)
as.data.frame(df_Gini)
df_Gini <- df_Gini %>% select(year = c(2), gini_eur = c(3), gini_nor = c(4))
#ORDENAR------------------------------------------------------------------------
df_productivity <- df_prod_plot %>% group_by(year) %>%
mutate(productivity = mean(index)) %>%
select(c(2,5)) %>%
distinct() %>%
ungroup()
df_tax_wedge <- df_calc %>% group_by(year) %>%
mutate(tax_wedge = mean(pp_wedge)) %>%
select(2,13) %>%
distinct() %>%
ungroup()
df_gini <- df_Gini %>% group_by(year) %>%
mutate(gini_index = gini_eur + gini_nor) %>%
mutate(gini_index = gini_index / 2) %>%
select(1,4) %>%
ungroup()
df_housing <- df_haus %>% group_by(year) %>%
mutate(housing = haus_eur + haus_nor) %>%
mutate(housing = housing / 2) %>%
select(1,4) %>%
ungroup()
df_market_cap <- df_market %>% group_by(year) %>%
mutate(market_cap = mean(market_cap)) %>%
select(2,3) %>%
ungroup() %>%
distinct()
df_inflation <- df_calc %>% group_by(year) %>%
mutate(inflation = mean(CPI)) %>%
select(2,13) %>%
ungroup() %>%
distinct() %>%
mutate(inflation_rate = (inflation / lag(inflation) - 1) * 100) %>%
select(1,3)
#GiNi = a + BTaxWedge + BMarketCap + BInflation + BLog(Productivity) + BLog(Housing)
df_modelo <- full_join(df_inflation, df_market_cap, by = join_by(year))
df_modelo <- full_join(df_modelo, df_gini, by = join_by(year))
df_modelo <- full_join(df_modelo, df_tax_wedge, by = join_by(year))
df_modelo <- full_join(df_modelo, df_housing, by = join_by(year))
df_modelo <- full_join(df_modelo, df_productivity, by = join_by(year))
df_modelo_original <- df_modelo %>% filter(year %in% c(2001:2023)) %>%
mutate(gini_index = gini_index * 100)
modelo_definitivo <- lm(
gini_index ~ log(tax_wedge) +
log(housing) +
log(productivity) +
market_cap +
inflation_rate,
data = df_modelo_original
)
summary(modelo_definitivo)
stargazer(modelo_definitivo, type = "text")
modelo_refinado <- step(modelo_definitivo, direction = "backward")
summary(modelo_refinado)
stargazer(modelo_refinado, type = "text")
df_modelo_original_pib <- df_modelo_original %>% full_join(df_GDP_, by = join_by(year))
df_modelo_original_pib <- df_modelo_original_pib %>% mutate(housing_pib = housing / gdp_aggre,
tax_wedge_pib = tax_wedge /gdp_aggre)
results <- lm(
gini_index ~ log(tax_wedge_pib) +
log(housing_pib) +
log(productivity) +
market_cap +
inflation_rate,
data = df_modelo_original_pib
)
summary(results)
stargazer(results, type = "text")
modelo_limpio <- step(results, direction = "backward")
summary(modelo_limpio)
stargazer(modelo_limpio, type = "text")
library(modelsummary)
library(gt)
library(dplyr)
mapa_nombres <- c(
"(Intercept)" = "Constante",
"log(tax_wedge_pib)" = "Cuña Fiscal (% PIB, log)",
"inflation_rate" = "Tasa de Inflación",
"log(productivity)" = "Producividad (log)",
"log(housing_pib)" = "Vivienda (% PIB, log)",
"market_cap" = "Cap Mercado (% PIB)"
)
msummary(
results,
output = "gt",
coef_map = mapa_nombres,
stars = c('*' = .1, '**' = .05, '***' = .01),
gof_map = c("nobs", "r.squared", "adj.r.squared", "F"),
title = "Tabla 1. Determinantes de la Desigualdad (Índice Gini)"
) %>%
tab_spanner(
label = "Modelo de desigualdad GINI OLS",
columns = everything()
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = 1)
) %>%
tab_source_note(
source_note = md("Notas: Errores estándar entre paréntesis. * p<0.1, ** p<0.05, *** p<0.01. Fuente: Elaboración propia.")
) %>%
opt_table_lines(extent = "default")
modelo_80 <- full_join(df_market_cap, df_housing)
modelo_80 <- modelo_80 %>% full_join(df_gini)
modelo_80_test <- modelo_80 %>% full_join(df_productivity)
modelo_80_test <- modelo_80_test %>% full_join(df_GDP_) %>%
filter(year %in% c(1980:2023))
modelo_80_test_ <- modelo_80_test %>% mutate(
#housinig_gdp = (housing / gdp_aggre) * 100,
gini_index = gini_index * 100)
modelo_80s <- lm(
gini_index ~ housing +
market_cap +
log(productivity),
data = modelo_80_test_)
summary(modelo_80s)
# Tabla bonita
stargazer(modelo_80s, type = "text")
library(gt)
library(broom)
library(dplyr)
# 1. PREPARAR LOS DATOS (Broom)
# Extraemos los coeficientes del modelo 'modelo_80s'
tabla_datos <- tidy(modelo_80s) %>%
mutate(
# A. Crear Estrellas de Significancia
stars = case_when(
p.value < 0.001 ~ "***",
p.value < 0.01 ~ "**",
p.value < 0.05 ~ "*",
p.value < 0.1 ~ ".",
TRUE ~ ""
),
# B. Renombrar Variables para que se lean bien
term = case_when(
term == "log(productivity)" ~ "Productividad(Log)",
term == "housing" ~ "Vivenda (Nominal)",
term == "market_cap" ~ "Stock Market Cap (% GDP)",
term == "(Intercept)" ~ "Constante",
TRUE ~ term
)
)
# Extraemos estadísticas globales (R2, N)
stats_modelo <- glance(modelo_80s)
tabla_final <- tabla_datos %>%
select(term, estimate, std.error, p.value, stars) %>%
gt() %>%
# --- TÍTULOS ---
tab_header(
title = md("**Drivers of Income Inequality (1980-2023)**"),
subtitle = md("*Time Series Analysis: Technology vs. Wealth*")
) %>%
# --- ETIQUETAS DE COLUMNA ---
cols_label(
term = "Variable",
estimate = "Coefficient",
std.error = "Std. Error",
p.value = "P-Value",
stars = "Sig."
) %>%
# --- FORMATO DE NÚMEROS ---
# IMPORTANTE: Usamos 5 decimales para ver el coeficiente de housing
fmt_number(
columns = c(estimate, std.error),
decimals = 5
) %>%
fmt_number(
columns = p.value,
decimals = 4
) %>%
# --- FUSIONAR ESTRELLAS CON COEFICIENTE (Estilo Paper) ---
cols_merge(
columns = c(estimate, stars),
pattern = "{1}{2}"
) %>%
# --- ESTÉTICA ---
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = term)
) %>%
tab_options(
table.border.top.color = "black",
table.border.bottom.color = "black",
column_labels.border.bottom.color = "black",
table.font.names = "Times New Roman",
heading.align = "left"
) %>%
# --- PIE DE PÁGINA (Estadísticas) ---
tab_source_note(
source_note = md(paste0(
"**Observations:** ", stats_modelo$nobs, " | ",
"**Adj. R-Squared:** ", round(stats_modelo$adj.r.squared, 3), " | ",
"**F-Statistic:** ", round(stats_modelo$statistic, 1)
))
) %>%
tab_source_note(
source_note = md("*Signif. codes: *** p<0.001; ** p<0.01; * p<0.05*")
)
tabla_final_con_notas <- tabla_datos %>%
select(term, estimate, std.error, p.value, stars) %>%
gt() %>%
# --- TÍTULOS ---
tab_header(
title = md("**Factores de la desigualdad (1980-2023)**"),
subtitle = md("*Análisis de series temporales*")
) %>%
# --- ETIQUETAS ---
cols_label(
term = "Variable",
estimate = "Coefficient",
std.error = "Std. Error",
p.value = "P-Value",
stars = "Sig."
) %>%
# --- FORMATOS ---
fmt_number(columns = c(estimate, std.error), decimals = 5) %>%
fmt_number(columns = p.value, decimals = 4) %>%
cols_merge(columns = c(estimate, stars), pattern = "{1}{2}") %>%
# --- ESTILO ---
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = term)
) %>%
tab_options(
table.border.top.color = "black",
table.border.bottom.color = "black",
column_labels.border.bottom.color = "black",
table.font.names = "Times New Roman",
heading.align = "left",
# Esto es para que las notas al pie se vean académicas
footnotes.font.size = "small"
) %>%
# --- AQUÍ ESTÁ LA MAGIA: NOTAS AL PIE ---
# NOTA 1: Específica para la Vivienda (Explica el coeficiente pequeño)
tab_footnote(
footnote = "Coeficiente representa el efecto nominal del precio del precio de la vivienda (en millones de unidades). Pequeña magnitud es debido a la escala de la variable.",
locations = cells_body(
columns = term,
rows = term == "Vivienda (Nominal)"
)
) %>%
# NOTA 2: Específica para la Productividad (Explica que es elasticidad)
tab_footnote(
footnote = "Variable log transformada. Coefficient es interpretado como la elasticidad.",
locations = cells_body(
columns = term,
rows = term == "Productividad(Log)"
)
) %>%
# --- PIE DE PÁGINA (Estadísticas + Fuente) ---
tab_source_note(
source_note = md(paste0(
"**Obs:** ", stats_modelo$nobs, " | ",
"**Adj. R²:** ", round(stats_modelo$adj.r.squared, 3), " | ",
"**F-Stat:** ", round(stats_modelo$statistic, 1)
))
) %>%
tab_source_note(
source_note = md("*Signif. codes: *** p<0.001; ** p<0.01; * p<0.05. Fuente: Banco Mundial & OECD.*")
)
# MOSTRAR
tabla_final_con_notas
```
El primer modelo es poco robusto debido a la posible multicolinealidad. Podemos observar que la productividad puede tener un efecto significativo sobre la desigualdad así como también la cuña fiscal.
Para corregirlo y que el modelo sea más robusto, he elegido solo las variables que ofrecen datos desde los años 80 para añadir más observaciones. A partir de este modelo obtenemos que la productividad afecta de manera significativa positivamente a la igualdad. Esto podría decirnos que podría haber una concentración del poder en manos de las rentas del capital. A simple vista esto podría alarmarnos porqué la revolución tecnológica de la inteligencia artificial podría magnificar aún más los efectos. Por otra parte, la variable del precio de la vivienda es también significativa negativa. Esto puede decirnos que un aumento del precio de la vivienda reduce la desigualdad ya que la mayor parte de la población (más de un 60% en España) posee dicho activo, por tanto, se ven beneficiados del aumento del precio y no solo unos pocos.
## Conclusión
La desigualdad no ha hecho más que crecer. El efecto es más notable en los países anglosajones que en Europa, cada vez más una parte pequeña de la población acapara más renta nacional. Según el análisis, podríamos inferir en qué la acumulación de capital ha hecho aumentar la riqueza a una parte pequeña de la población que la posee en detrimento de la parte de la población que depende de las rentas del trabajo. Este poder de mercado podría verse empeorado en un futuro si no se tiene en cuenta sus efectos adversos.
## Webgrafía
- Our World in Data: [https://ourworldindata.org/](https://ourworldindata.org/) <br>
- Banco Mundial: [https://www.bancomundial.org/ext/es/home](https://www.bancomundial.org/ext/es/home) <br>
- OCDE: [https://www.oecd.org/en.html](https://www.oecd.org/en.html) <br>
- WID: [https://wid.world/data/](https://wid.world/data/) <br>